【Hadoop 分布式部署 三:基于Hadoop 2.x 伪分布式部署进行修改配置文件】
1.规划好哪些服务运行在那个服务器上

需要配置的配置文件

2. 修改配置文件,设置服务运行机器节点
首先在 hadoop-senior 的这台主机上 进行 解压 hadoop2.5 按照伪分布式的配置文件来进行配置
使用命令 :tar -zxvf hadoop-2.5.0.tar.gz -C /opt/app/ (解压 hadoop 2.5)
然后进入 cd /opt/app/hadoop-2.5.0/etc
将里面一开始的配置文件重命令 mv hadoop backup-hadoop
然后将一开始伪分布式中的配置文件复制过来 使用命令 cp -r /opt/moudles/hadoop-2.5.0/etc/hadoop ./
(如果在Windows下 想使用方便,可以在C:\Windows\System32\drivers\etc目录下 修改hosts文件 配置 虚拟机的主机IP)

开始配置
使用notepad 进行配置hadoop 的配置文件
hadoop.env export JAVA_HOME=/opt/modules/jdk1.7.0_67 (默认已经配置好了,不用更改)
core-site.xml 文件中的内容配置
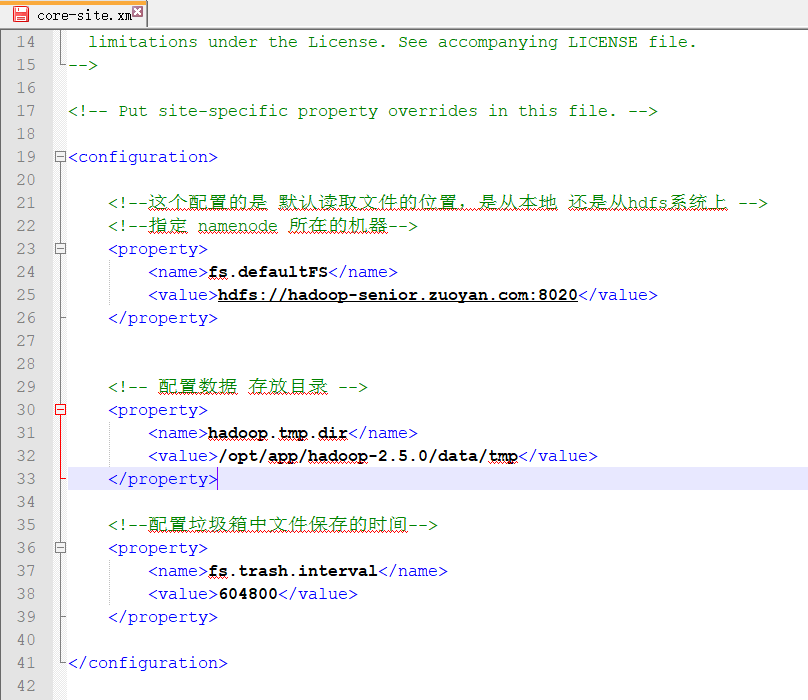
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | <configuration> <!--这个配置的是 默认读取文件的位置,是从本地 还是从hdfs系统上 --> <!--指定 namenode 所在的机器--> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-senior.zuoyan.com:8020</value> </property> <!-- 配置数据 存放目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/app/hadoop-2.5.0/data/tmp</value> </property> <!--配置垃圾箱中文件保存的时间--> <property> <name>fs.trash.interval</name> <value>604800</value> </property> </configuration> |
因为没有数据存放的目录 所以需要配置一下 hadoop.tmp.dir 的目录
命令 : mkdir -p /opt/app/hadoop-2.5.0/data/tmp
配置hdfs
首先配置hdfs-site.xml 文件
因为是分布式 所以不需要配置副本数 去掉 dfs.replication
配置SecondaryNameNode 所在的节点 dfs.namenode.secondary.http-address hadoop-senior03.zuoyan.com

<configuration>
<!--配置secondary namenode 所在的主机-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-senior03.zuoyan.com:50090</value>
</property>
</configuration>
配置slaves 也就是配制 DataNode NodeManager
配置的内容为
1 2 3 | hadoop-senior.zuoyan.comhadoop-senior02.zuoyan.comhadoop-senior03.zuoyan.com |
配置yarn
首先配置 yarn.env 配置yarn的环境变量 (我这里已经配置好了,就不用更改了)

配置yarn-site.xml 这个文件
这个配置文件只需要 将 resourcesmanager 所在的主机节点更改成第二台主机就可以了
剩下的配置文件不用修改,配置文件内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--配置resourcemanager 所在的主机名 --> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop-senior02.zuoyan.com</value> </property> <!--启用历史服务器的日志聚集功能--> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!--设置日志在文件系统上的存放时间--> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>640800</value> </property> <!--配置NodeManager Resource--> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <property> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> </configuration> |
配置 mapred-site.xml
配置 JobHistoryServer 的配置文件 资源设计的时候 就把他放在了第一台主机上,所以 保持默认配置文件即可,修改一下主机名就行
配置文件的内容如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!--配置历史记录服务器所在地址--> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop-senior.zuoyan.com:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop-senior.zuoyan.com:19888</value> </property></configuration> |
到此,配置文件就配置完成了!下一步就是分发到各个机器上去
(还有一个小点就是 删除 在 /opt/app/hadoop-2.5.0/share 下的 doc文件夹,这个文件是文档,我们一般,不用,而且还占用磁盘空间 大概占用的磁盘空间是1.5G )
好了,这篇随笔就到这里了,下一篇继续!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号
【推荐】100%开源!大型工业跨平台软件C++源码提供,建模,组态!
【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】Flutter适配HarmonyOS 5知识地图,实战解析+高频避坑指南
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 理解 C# 中的各类指针
· C#多线程编程精要:从用户线程到线程池的效能进化论
· 如何反向绘制出 .NET程序 异步方法调用栈
· 领域驱动设计实战:聚合根设计与领域模型实现
· 突破Excel百万数据导出瓶颈:全链路优化实战指南
· 理解 C# 中的各类指针
· DeepSeek+Coze实战:从0到1搭建小红书图文改写智能体(喂饭级教程)
· 【SQL周周练】一千条数据需要做一天,怎么用 SQL 处理电表数据(如何动态构造自然月)
· C#/.NET/.NET Core技术前沿周刊 | 第 37 期(2025年5.1-5.11)
· 如何医治一条慢SQL?