G1垃圾收集器工作机制梳理
Java语言的神奇之处就在于,代码开发者从来不需要考虑回收不用的对象,因为顶层的JVM虚拟机会自动帮你完成这些事情,这种特质是优势也是劣势,正如围城中所言,城外的人想进去,城里的人想出来!
自JDK1.9开始,G1垃圾收集器已经是默认的JVM垃圾回收器了,所以对于Java开发者而言,我们需要了解并知晓其中原理,拥抱变化,不能因为自己仍然在使用JDK1.8就对“新的”垃圾回收器不管不问;
好啦,正式进入正题之前, 先大概了解几个知识点!

在G1中,对堆内存区域的划分仍然有新生代老年代的概念,但是其内存空间不再连续,正如上图所示,G1将一个完整的堆内存空间进行了分块,每一块称之为一个region,总共有4种类型的region,他们分别是Eden伊甸园区,survivor区, old区(老年代),Humongous区(大对象区)这四种类型,并且每个区域不再是固定,也就是说垃圾回收的动作发生之前可能是新生代的区域,垃圾回收之后可能变成survivor或者是老年代了;
默认参数下,不管分配的堆内存空间多大,G1垃圾回收器都会将其分成2048份;
G1内部细节
- 无需回收整个堆,而是选择一个Collection Set(CS)
- 一共有两种GC,Fully Young GC 和 Mixed GC
- 估计每个region中的垃圾比例,优先回收垃圾多的Region(这也是G1名字的由来)
将整个堆划分成多个小region,不再按照分代为最小粒度进行收集,而是按照region为最小单位进行收集的思想会带来什么问题呢?那就是跨代引用的问题,以G1的 Fully Young GC为例,触发清理的条件就是当Eden区满了的时候就会触发young GC的垃圾回收,可是只清理Eden标志的Region真的可行吗? 答案是不可行;因为Eden区中可能有很多对象,在整个Region区中并找不到引用它的对象,但是这种情况下JVM并不能认为它是可以回收的,很有可能在Old区中仍然存在某些对象引用了这个Eden区中的对象,这时如果盲目的删掉的话,势必会造成程序的崩溃,可以用两张图来说明一下这个case:
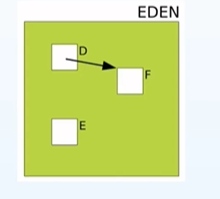
JVM真的可以删除掉这个E吗?
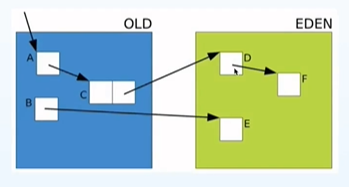
这种情况下还可以删除E这个对象吗?答案肯定是不行的
我们替JVM进一步考虑一下,有办法来解决这种情况吗?当然可能有的同学会说全堆扫描,没错,全堆扫描确实可以解决这个问题。但是这就违背了G1垃圾回收器的软实时,低时延的设计初衷了呀,肯定不行!
接下来就是另外两个重要的结构登场了!为了解决这个问题,JVM采用了两个重要的数据结构,卡表和记忆集!
卡表是什么呢?你可以把它理解成对一块内存区域的粗略划分,如果你想对内存区域进行划分,可以划分成什么粒度呢?假设我们每个Region都是1M,你可以按照KB进行划分,分成1024个,按照字节进行划分,可以分成1024*1024个,按照bit进行划分,又可以更精细一些,但是从垃圾收集器的角度来说,有这个必要吗?我认为没有
G1是怎么做的呢,我们对一个1M大小的Region进行划分,按照512B为一份,那么可以分成2000份,每当有其他Region的对象对我Region的对象进行了引用,我记录下是哪个Region,然后再利用卡表对它进行一次粗略的划分,就可以大概知道引用我的对象到底在其他哪个region,甚至可以精细化到512B的粒度,维护起这样一个数据结构之后,
每当我需要回收某个region的时候,我就去读一下我这个region维护的remember set(RS)就可以知道所有引用我的region是哪些,再利用卡表进行精细化的划分,甚至可以知道到底是region的哪块内存区域了!到时候一起加入进来,然后整体利用可达性分析,进行一波trace,不就能够给出正确的结论了吗?妙啊!!!!
这是空间换时间的经典应用场景,可是问题又来了,什么时候去维护这个记忆集呢?要知道,对象赋值的过程,在java里面实在是太太太多了,我们直接来看解法;
是通过write barrier的方式来维护的,write barrier会在每个赋值动作发生的时候,去标记被引用 对象的记忆集里面的卡表为脏的,但是更新不是立即发生的,而是维护了一个队列,又另外的线程来异步的进行更新;

这个队列称之为Dirty Card Queue队列
这个队列它有4种颜色,分别为白/绿/黄/红 分别代表了队列存储的卡表的数量及其严重程度!
如果颜色为绿色,这时候Refinement的线程就开始被激活,开始更新RS
如果颜色为黄色,那么此时所有的Refinement线程都会全力以赴的更新RS!
而如果是红色就更不得了了,JVM会让用户线程也参与到RS的更新当中!

介绍完这些之后,我们正式来看一下G1的垃圾回收的完整过程,其实对于G1垃圾收集器而言,整个过程大概分为三部分:
1.Fully Young GC(年轻代GC)
2.老年代全局并发标记过程(Global Marking)
3.Mixed GC(混合GC的收集过程)
extra: Fully GC(当fully Young GC + Mixed GC的工作模式没办法cover线上对象的生成速度的时候,产生STW,然后使用 serial Old的单线程收集器的方式来进行垃圾的收集,非预期的情况,一旦出现需要进行调优)
1.Fully Young GC过程
整个过程分为以下几个步骤:
1. 构建Collection Set
2. 扫描GC Root
3. 更新RS (白绿黄红,处理Dirty Card Queue,更新RS)
4.处理RS (找到哪些对象被老年代引用)
5. Object Copying(使用标记-复制算法进行对象的移动)
6. Reference Processing(重新处理引用关系)
流程完整的示意图可以看下图:
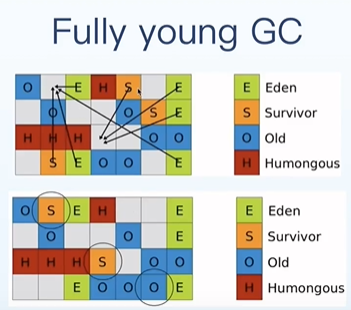
通过上图我们也能够看出,对Eden区和Survivor区进行垃圾收集,然后将仍然存活的对象,放到白色的未使用的区域当中,复制算法实现的,然后清理掉之前的Eden和Survivor区,重新变成白色,这也是我文章开头说的为什么Region的逻辑属性会不断发生变化的原因!
对于Fully Young GC而言就算是结束了,但是G1垃圾收集器在这个时候其实还偷偷帮我们做了以下几件事情:
- 记录每个阶段的时间,用于自动调优
- 记录Eden/Survivor的数量和GC的时间(根据暂停目标自动调整Eden区的数量,暂停目标越短,Eden数量就会越调整越少,对G1的压迫越狠,相应的Eden区域的数量就会慢慢变少,导致young gc的时延变短,但是次数慢慢变多,吞吐量开始下降)
这里第二条有一个非常有意思的点,年轻代GC其实也有一个Balance的过程,那就是首先他会记录回收年轻代到底使用了多少的时间,如果这个时间小于你在G1 GC调优里面配置的参数的话,G1收集器会继续增加Eden区的数量来逐渐逼近你期望的这个停顿时间;所以你如果不断的减小你的期望停顿时间,不断的对G1进行压迫的话,其实最终会不断的降低你的新生代空间的比例,最终导致频繁的Fully Young GC的过程;
2.老年代全局并发标记过程
触发条件:当堆用量达到一定程度的时候会触发(-XX:InitiatingHeapOccupancyPercent 默认为45%),当堆用量达到了45%的时候,这时候G1收集器感觉有点不妙,可能就会触发全局并发标记的过程;
这里我为什么要加可能呢,是因为就算你堆的用量这时候达到了45%的一个阈值,全局并发标记也不是立刻就会触发的,这时候它会等待下一次年轻代GC的触发,然后紧随着年轻代GC进行一次全局并发标记;
是因为这样的话全局并发标记的过程可以一定程度上复用了年轻代GC的初始标记的阶段!
看一下全局并发标记的完整流程:
- 初始标记(Fully Young GC执行完成的) 需要STW
- 恢复用户线程
- 全局并发标记(不需要STW,和用户线程一起执行)
- 并发重新标记(需要STW,用来纠正并发标记的时候用户线程的继续执行导致的引用更新的问题, SATB snapshot at the begining)
- 立刻回收全空的区域,并不执行拷贝操作,而是只找全空的区域进行立刻清理
- 恢复用户线程
这里再思考一个问题,为什么发现了老年代当中某个region有垃圾了,而再old GC的过程中不对它进行清理呢?是因为如果一旦针对某个region使用了老年代的标记-整理算法的话,对于这个region而言,是不会有碎片产生的,但是从整个堆的角度上看的话,结果还是有大量的碎片出现了
那么什么时候去执行真正的清理呢?G1的特色来了,那就是mixed GC
3.Mixed GC的完整流程
Mixed GC(不一定立即发生)
- 选择若干个region进行,默认是选择1/8的Old Region进行
- Eden + Survivor区 (同时回收了新生代和老年代,所以叫mixed GC)
- 使用的算法是ParallelNew 标记复制算法,需要 STW
- 根据暂停的预期的目标,优先选择垃圾最多的老年代执行,回收价值最大
之后我仔细的整理了一下这个过程,其实Mixed GC的过程和Fully Young GC基本上是一致的,而且它利用的是第二个阶段的全局并发标记的tracing的结果,
所以硬要说和Fully Young GC的不同之处的话,那就是Fully Young GC它是根据EDEN + suvivor区域再加上RS的老年代部分内存合起来作为整个CS进行trace并执行垃圾收集的
而我们的Mixed GC它其实是利用了第二个阶段的全局并发标记过程,完整的梳理了一遍整个堆上的所有region到底哪些区域里面有垃圾,有多少垃圾,然后根据停顿时间给出一个回收
策略的最优解这样子,完成MixedGC的垃圾回收的过程;
整个过程见下图:

用大白话讲就是,Mixed GC这个阶段会同时回收新生代和老年代,它回收的老年代的对象是Old GC过程中trace 标记出来的那些标记为可以回收的对象,根据老年代Region中可以回收的对象的数量和统计的回收时间,优先选择出top 1/8的老年代region,然后统一的执行复制算法,将那些仍然存活的分散于各个老年代region的存活对象,都聚集到一起去,比如上图中都聚集到了一个O里面,这样就完成了Mixed GC的过程啦
第一次详细窥探G1的原理,难免有理解不到位的地方,如果有误,欢迎大家留言指出,我会第一时间纠正,不误人子弟~


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】Flutter适配HarmonyOS 5知识地图,实战解析+高频避坑指南
【推荐】凌霞软件回馈社区,携手博客园推出1Panel与Halo联合会员
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 领域驱动设计实战:聚合根设计与领域模型实现
· 突破Excel百万数据导出瓶颈:全链路优化实战指南
· 如何把ASP.NET Core WebApi打造成Mcp Server
· Linux系列:如何用perf跟踪.NET程序的mmap泄露
· 日常问题排查-空闲一段时间再请求就超时
· c#开发完整的Socks5代理客户端与服务端——客户端(已完结)
· c# 批量注入示例代码
· 【Uber 面试真题】SQL :每个星期连续5星评价最多的司机
· .net core workflow流程定义
· 将数据导出 Excel 并异步发送到指定邮箱:一次性能优化实战