
从零自学Hadoop(15):Hive表操作
阅读目录
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink
序
上一篇,我们介绍了Hive和对其进行了安装,下面我们就初步的使用hive进行讲解。
下面我们开始介绍hive的创建表,修改表,删除表等。
创建表
一:Hive Client
在Terminal输入hive命令需要安装Hive Client。
二:进入
切换用户,进入hive
su hdfs hive
三:创建表
语法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, ...)];例子:
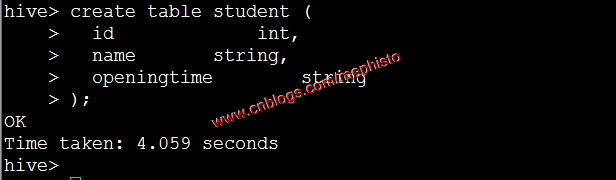
create table student ( id int, name string, openingtime string );
四:创建带有分区的表
介绍:
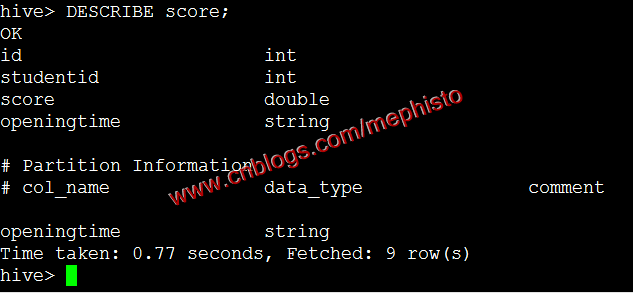
一个表可以拥有一个或者多个分区,每个分区以文件夹的形式单独存在表文件夹的目录下。分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。在Hive Select查询中一般会扫描整个表内容,会消耗很多时间做没必要的工作。有时候只需要扫描表中关心的一部分数据,因此建表时引入了partition概念。表中的一个 Partition 对应于表下的一个目录,Partition 就是辅助查询,缩小查询范围,加快数据的检索速度和对数据按照一定的规格和条件进行管理。
语法:
create table table_name ( id int, dtDontQuery string, name string ) partitioned by (date string)例子:
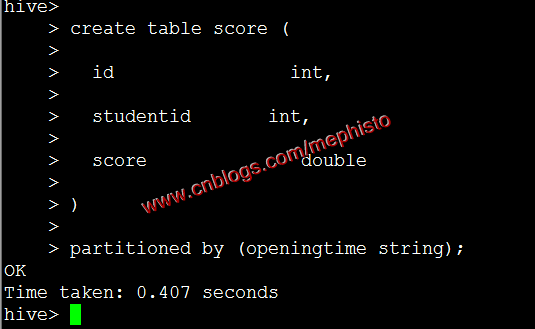
create table score ( id int, studentid int, score double ) partitioned by (openingtime string);


查看表
一:查看所有表
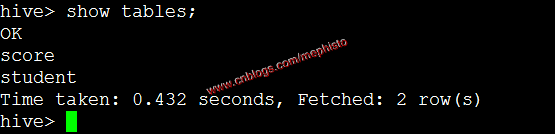
show tables;
二:查看某个表信息
我们通过Desctribe来显示某个表的信息
语法:
DESCRIBE DATABASE [EXTENDED] db_name; DESCRIBE SCHEMA [EXTENDED] db_name; -- (Note: Hive 0.15.0 and later) --------------------------------------------------------------------------------- DESCRIBE [EXTENDED|FORMATTED] [db_name.]table_name[.col_name ( [.field_name] | [.'$elem$'] | [.'$key$'] | [.'$value$'] )* ]; -- (Note: Hive 1.x.x and 0.x.x only) -- (see "Hive 2.0+: New Syntax" below)例子:
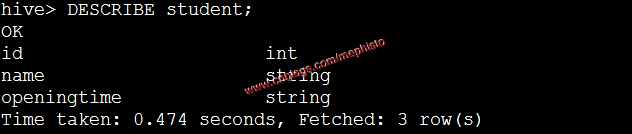
DESCRIBE student;DESCRIBE score;
三:查看某列信息
DESCRIBE student.id;

修改表
一:改表名
语法:
ALTER TABLE table_name RENAME TO new_table_name;例子:
alter table student rename to student1;
二:修改列
语法:
ALTER TABLE table_name [PARTITION partition_spec] CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name] [CASCADE|RESTRICT];例子:
alter table student1 change name name1 string;
三:增加/替换列
语法:
ALTER TABLE table_name [PARTITION partition_spec] ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...) [CASCADE|RESTRICT]例子:
alter table student1 add columns (sex int);



删除表
一:删除表
语法:
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];例子:
drop table score;
--------------------------------------------------------------------
到此,本章节的内容讲述完毕。

系列索引
本文版权归mephisto和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作。
文章是哥(mephisto)写的,SourceLink


博文作者:mephisto
本文版权归作者和博客园共有,欢迎转载,但须保留此段声明,并给出原文链接,谢谢合作!
如果阅读了本文章,觉得有帮助,您可以选择捐助我:




【推荐】凌霞软件回馈社区,携手博客园推出1Panel与Halo联合会员
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 当数据爆炸遇上SQL Server:优化策略全链路解析
· 记录一次线上问题排查:JDK序列化问题
· 微服务之间有哪些调用方式?
· 记一次SQL隐式转换导致精度丢失问题的排查
· dotnet 9 通过 AppHostRelativeDotNet 指定自定义的运行时路径
· 一个基于 C# Unity 开发的金庸群侠传 3D 版,直呼牛逼!
· SQL Server 2025 中的改进
· 向商界大佬一样管理技术工作 - 以团队换将+技术重构为例
· 用c#从头写一个AI agent,实现企业内部自然语言数据统计分析(三)--一个综合的例子
· Qwen3接入评测,最强开源模型更懂Graph了吗?